Unsupervised learning using k-means clustering in Ruby
In this blog post we will solve a unsupervised clustering problem in Ruby. We will be using the rubygem kmeans-clusterer to setup the problem and cluster the data using the k-mean clustering algorithm.
The k-mean clustering algorithm is an algorithm used to divide unlabeled data into a number of clusters of related data. It is used for problems such a market segmentation, social network analysis, computer cluster analysis and astronomical data analysis.
For our example we pretend we are starting a beer distribution business in California. We want to use clustering to divide the market into X distribution territories (also called clusters), and understand the best location for our distribution centers. To simplify the problem we are only looking at the locations of cities when dividing the market. We will be ignoring other factors such as population, traffic patterns etc.
Data
As input data we use a list of the 100 most populous cities in California. The cities are provided in a comma separated files with the following columns:
- Name
- Latitude
- Longitude
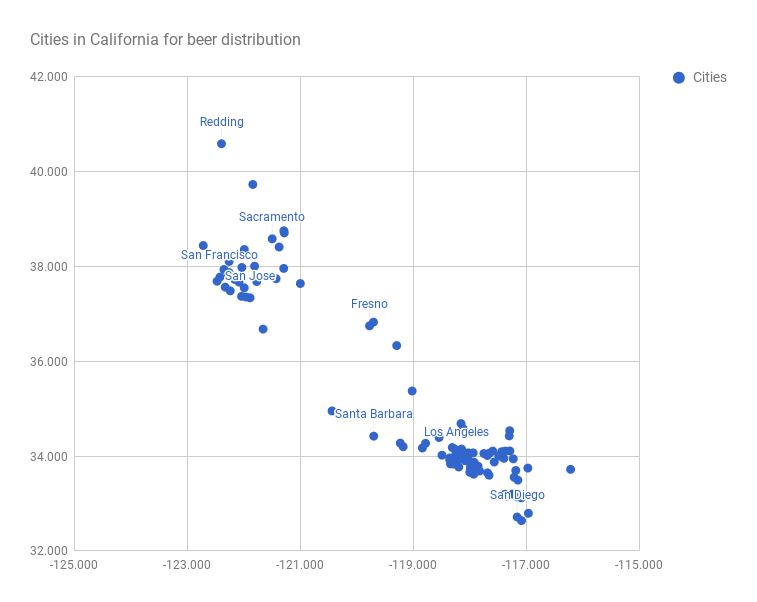
If we plot the data with the latitude as the y-axis and the longitude on the x-axis, we can see how the cities almost form natural clusters. We will be using the k-means clustering algorithm to properly define the clusters, and determine how many clusters to divide the state into.
Implementing k-means clustering
In order to get started we first install the kmeans-clusterer rubygem. We do this by either adding it to your gemfile file or by running the following on the command line:
$ gem install kmeans-clusterer
Next we open an empty ruby file and start by requiring the csv library, used for reading our data file, and the kmeans-clusterer gem like this:
require 'csv' require 'kmeans-clusterer'
Next we load or data into two arrays. One holds the city names called labels, and one holds the latitude and longitude of the cities called data.
data = []
labels = []
# Load data from CSV file into two arrays - one for latitude and longtitude data and one for labels
CSV.foreach("./data/cities.csv", :headers => false) do |row|
labels.push( row[0] )
data.push( [row[1].to_f, row[2].to_f] )
end
With our data loaded we can setup the k-means cluster algorithm and run clustering on our data. If we wanted to divide our data into 3 clusters we could do as follows:
k = 3 # Number of clusters to find
kmeans = KMeansClusterer.run k, data, labels: labels, runs: 100
kmeans.clusters.each do |cluster|
puts "Cluster #{cluster.id}"
puts "Center of Cluster: #{cluster.centroid}"
puts "Cities in Cluster: " + cluster.points.map{ |c| c.label }.join(",")
end
This will print out the 3 clusters with the center of the cluster (aka best location of distribution center) in latitude and longitude, as well as the city names included in the cluster like this:
$ ruby clustering.rb Cluster 0 Center of Cluster: [33.83551612903226, -117.77248387096779] Cities in Cluster: Orange,CA,Santa Ana,Anaheim,Fullerton,Irvine,Garden Grove,Chino,Lake Forest, CA,Corona,Pomona,Buena Park,Westminster,CA,Costa Mesa, CA,Ontario, CA,Mission Viejo,Newport Beach,West Covina,Hu ntington Beach,Whittier, CA,Norwalk, CA,Rancho Cucamonga,Jurupa Valley,El Monte,Downey,Riverside,Fontana,Long Beach,Alhambra, CA,Compton,South Gate,Rialto,Pasadena,Carson,Los Angeles,Moreno Valley,San Bernard ino,Torrance,Glendale,Hawthorne,Inglewood,Menifee,Murrieta,Burbank,Temecula,Santa Monica,Oceanside,Hesperia,Carlsbad,Hemet,Palmdale,Vista,Victorville,San Marcos, CA,Lancaster, CA,Santa Clarita,Escondido,Simi Valley,Thousand Oaks,San Diego,El Cajon,Chula Vista,Indio Cluster 1 Center of Cluster: [38.024033333333335, -121.9356333333333] Cities in Cluster: Concord, CA,Antioch,Fairfield,CA,Vallejo,Vacaville,Berkeley,San Leandro,Livermore,Hayward,Oakland,Richmond, CA,Fremont,San Francisco,Tracy,San Mateo, CA,Redwood City,Daly City,Stockton,Sunn yvale,Santa Clara,Elk Grove,San Jose,Sacramento,Santa Rosa,Citrus Heights,Roseville,Modesto,Salinas,Chico,Redding Cluster 2 Center of Cluster: [35.39025, -119.540875] Cities in Cluster: Bakersfield,Visalia,Santa Barbara,Santa Maria,Ventura,Oxnard,Fresno,Clovis
While this is useful it is not quite what we are looking. We wanted to not only divide the cities into distribution areas, but also determine the optimal number of distribution areas.
Finding the optimal number of clusters
To find the optimal number of clusters to divde our data into we use the so called “elbow method”. To use the elbow method we need to plot the error when using different number of clusters. The error we use is a measure of how far the different points are from the closest cluster center.
To calculate the error at different number of clusters we run the following:
2.upto(20) do |k|
kmeans = KMeansClusterer.run k, data, labels: labels, runs: 100
puts "Clusters: #{k}, Error: #{kmeans.error.round(2)}"
end
This gives the following output:
$ ruby clustering.rb Clusters: 2, Error: 86.3 Clusters: 3, Error: 57.32 Clusters: 4, Error: 42.85 Clusters: 5, Error: 33.03 Clusters: 6, Error: 25.83 Clusters: 7, Error: 21.02 Clusters: 8, Error: 17.0 Clusters: 9, Error: 14.91 Clusters: 10, Error: 13.0 Clusters: 11, Error: 11.49 Clusters: 12, Error: 10.39 Clusters: 13, Error: 9.33 Clusters: 14, Error: 8.28 Clusters: 15, Error: 7.18 Clusters: 16, Error: 6.61 Clusters: 17, Error: 5.84 Clusters: 18, Error: 5.2 Clusters: 19, Error: 4.73 Clusters: 20, Error: 4.21
Plotting this error data gives the following plot:

Looking at the chart we can determine the optimal amount of clusters by pretending the curve is an arm and determining where the elbow of the arm would be. In our example it is around 7 clusters as illustrated below:
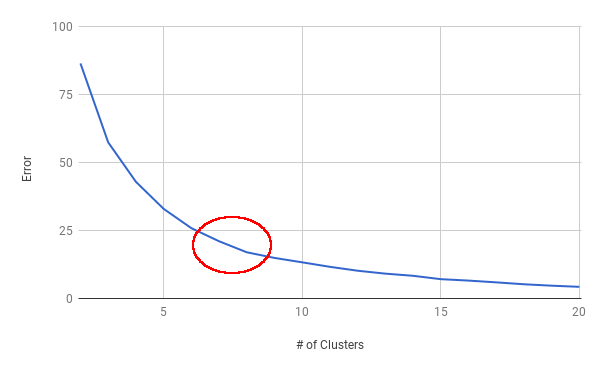
Obviously this is not an exact science, and this will only give you an indicator of the which amount of clusters to select rather than the final answer. In reality you would take other factors into account when determining the right amount of clusters for your problem.
Clustering our data
Having determined we need 7 clusters or distribution centers for our beer distribution operation we proceed to cluster the data into 7 distribution areas like this:
k = 7 # Optimal K found using the elbow method
kmeans = KMeansClusterer.run k, data, labels: labels, runs: 100
kmeans.clusters.each do |cluster|
puts "Cluster #{cluster.id}"
puts "Center of Cluster: #{cluster.centroid}"
puts "Cities in Cluster: " + cluster.points.map{ |c| c.label }.join(",")
end
Running this code gives us the following output:
$ ruby clustering.rb Cluster 0 Center of Cluster: [36.634, -119.58933333333334] Cities in Cluster: Fresno,Clovis,Visalia Cluster 1 Center of Cluster: [33.98345652173913, -117.93210869565219] Cities in Cluster: West Covina,Whittier, CA,Fullerton,El Monte,Buena Park,Anaheim,Norwalk, CA,Pomona,Downey,Garden Grove,Orange,CA,Alhambra, CA,Westminster,CA,Chino,Santa Ana,Pasadena,South Gate,Ontario, CA,Compton,Irvine,Los Angeles,Huntington Beach,Long Beach,Costa Mesa, CA,Glendale,Rancho Cucamonga,Newport Beach,Carson,Corona,Lake Forest, CA,Inglewood,Burbank,Hawthorne,Torrance,Jurupa Valley,Mission Viejo,Fontana,Riverside,Santa Monica,Rialto,Palmdale,San Bernardino,Santa Clarita,Lancaster, CA,Hesperia,Victorville Cluster 2 Center of Cluster: [40.1575, -122.11449999999999] Cities in Cluster: Redding,Chico Cluster 3 Center of Cluster: [38.268, -121.392] Cities in Cluster: Elk Grove,Stockton,Sacramento,Citrus Heights,Roseville,Tracy,Vacaville,Modesto Cluster 4 Center of Cluster: [33.2945, -117.09985714285712] Cities in Cluster: San Marcos, CA,Vista,Escondido,Temecula,Murrieta,Carlsbad,Oceanside,Menifee,Hemet,El Cajon,San Diego,Chula Vista,Moreno Valley,Indio Cluster 5 Center of Cluster: [34.52285714285714, -119.31114285714285] Cities in Cluster: Ventura,Oxnard,Santa Barbara,Simi Valley,Thousand Oaks,Bakersfield,Santa Maria Cluster 6 Center of Cluster: [37.713100000000004, -122.13519999999998] Cities in Cluster: San Leandro,Hayward,Oakland,Berkeley,Fremont,San Mateo, CA,Redwood City,Concord, CA,San Francisco,Richmond, CA,Daly City,Sunnyvale,Livermore,Santa Clara,Vallejo,Antioch,San Jose,Fairfield,CA,Santa Rosa,Salinas
To further illustrate our clustering algorithm I plotted all of our cities again, this time color coded to the cluster the k-means clustering algorithm determined it belongs to.

This shows how to use k-mean clustering for a simple two dimensional clustering problem, namely dividing a market into multiple distribution territories. Unsupervised learning and k-mean clustering can be used for many other applications, such as astronomical data analysis, social network analysis, communication cluster analysis and many other applications.
Hi, nice post thanks!
What support do you use to plot these things?
Thanks in advance!
For this post I exported the data and created the plots in Google Sheets.
Can you please share “CSV” file or tell me some of the entries in CSV file?
How can we identify the suitable value of “k” prgrammitcally instead of looking at graph?
This falls into a class of problem that is called NP-hard (see [1]). Which basically means there is no optimal way of finding that via a computer algorithm.
Your best bet is by knowing your data and making educated guesses/heuristics on a case by case basis.
[1] https://link.springer.com/chapter/10.1007%2F978-3-642-00202-1_24