Understanding Transformer model architectures
Transformers are a powerful deep learning architecture that have revolutionized the field of Natural Language Processing (NLP). They have been used to achieve state-of-the-art results on a variety of tasks, including language translation, text classification, and text generation. One of the key strengths of transformers is their flexibility, as they can be adapted to a wide range of tasks and problems by changing their architecture.
However, not every transformer model is the same; there are varying architectures, and picking the right one for the task at hand is important to get the best results.
Here we will explore the different types of transformer architectures that exist, the applications that they can be applied to and list some example models using the different architectures.
Encoder-Decoder
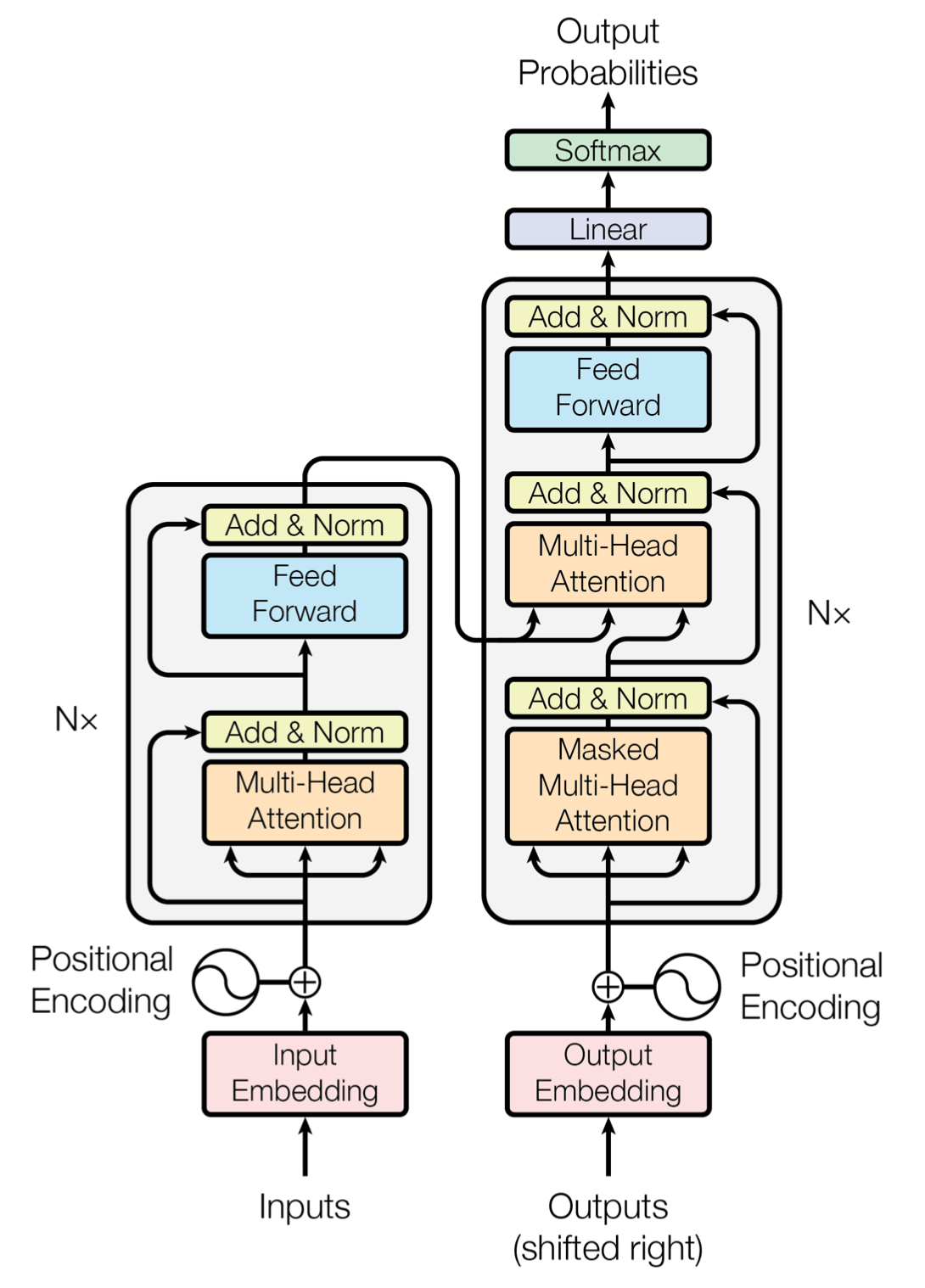
The Encoder-Decoder architecture was the original transformer architecture introduced in the Attention Is All You Need (https://arxiv.org/abs/1706.03762) paper.
It works as follows: the encoder (on the left) processes the input sequence and generates a hidden representation that summarizes the input information. The decoder (on the right) uses this hidden representation to generate the desired output sequence. The encoder and decoder are trained end-to-end to maximize the likelihood of the correct output sequence given the input sequence.
This mapping of the input sequence to output sequence makes these types of models suitable for applications like:
- Translation
- Text summarization
- Question and answering
Example models using this architecture are:
- T5 – Exploring the Limits of Transfer Learning with a Unified Text-to-Text Transformer (https://arxiv.org/pdf/1910.10683)
- BART: Denoising Sequence-to-Sequence Pre-training for Natural Language Generation, Translation, and Comprehension (https://arxiv.org/abs/1910.13461)
- Longformer: The Long-Document Transformer (https://arxiv.org/pdf/2004.05150)
Encoder-only
The Encoder-only architecture, on the other hand, is used when only encoding the input sequence is required and the decoder is not necessary. Here the input sequence is encoded into a fixed-length representation and then used as input to a classifier or a regressor to make a prediction.
These models have a pre-trained general-purpose encoder but will require fine-tuning of the final classifier or regressor.
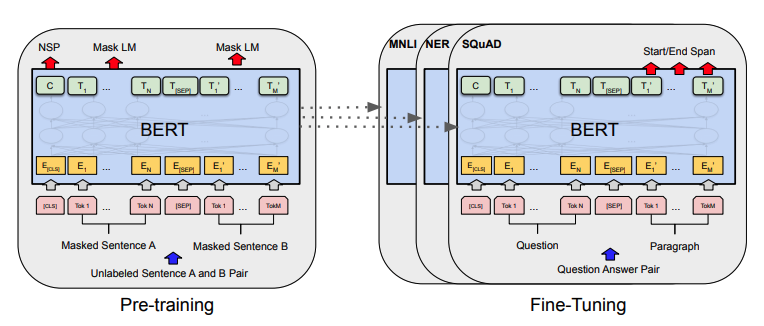
This output flexibility makes them useful for many applications, such as:
- Text classification
- Sentiment analysis
- Named entity recognition
Example models using this architecture are:
- BERT (https://arxiv.org/abs/1810.04805)
- DistilBERT (https://arxiv.org/abs/1910.01108)
- RoBERTa (https://arxiv.org/abs/1907.11692)
Decoder-only
In the Decoder-only architecture, the model consists of only a decoder, which is trained to predict the next token in a sequence given the previous tokens. The critical difference between the Decoder-only architecture and the Encoder-Decoder architecture is that the Decoder-only architecture does not have an explicit encoder to summarize the input information. Instead, the information is encoded implicitly in the hidden state of the decoder, which is updated at each step of the generation process.
This architecture is useful for applications such as:
- Text completion
- Text generation
- Translation
- Question-Answering
- Generating image captions
Example models using this architecture are:
- Generative Pre-Training models (https://s3-us-west-2.amazonaws.com/openai-assets/research-covers/language-unsupervised/language_understanding_paper.pdf) also called GPT models such as GPT-3, ChatGPT and GPT-J
- Google LaMDA (https://arxiv.org/pdf/2201.08239)
- OPT: Open Pre-trained Transformer Language Models (https://arxiv.org/abs/2205.01068)
- BLOOM: BigScience Large Open-science Open-access Multilingual Language Model (https://bigscience.huggingface.co/blog/bloom)