In this blog post I will show how to implement a support vector machine (SVM) in Ruby, and how to use it to solve a simple classification problem. We will be using the RubyGem rb-libsvm to help us setup a SVM, train it and make predictions in a minutes.
For our dataset we will be using school admission data, this was also the dataset used for in the Implementing Classification using Logistic Regression in Ruby, and in the Implementing Simple Classification using a Neural Network in Ruby blog post, so we will be able to compare the results and determine which approach is better at solving this problem.
You can find the full sample code used in this blog post here.
Data
The school admission data we are using have 3 rows for each example:
- Result of exam 1 (between 0 and 100)
- Result of exam 2 (between 0 and 100)
- Admission (1 for admitted, 0 if not admitted)
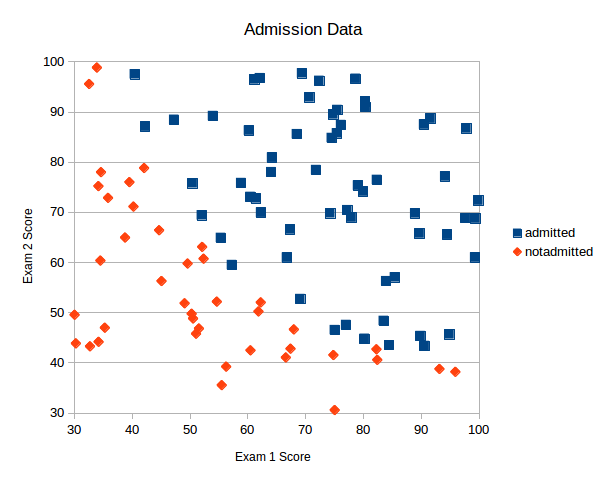
Plotting this data we see that there is clearly an correlation between the results of the exams and admission so we should be able to solve this problem using this data and a SVM.
Implementing SVM in Ruby
To get started implementing the SVM in Ruby we are going to install the rb-libsvm gem. The rb-libsvm gem is a an wrapper for the libsvm C library. LibSVM is a C library implementing fast support vector machines with support for a multitude of kernel implementations. To install the gem we run the following:
gem install rb-libsvm
With the gem installed we open an empty ruby file and start by requiring the libsvm library and the csv library for loading our data.
require 'csv' require 'libsvm'
Next we will load our data from our CSV file into an array for our independent variables (exam 1 score and exam 2 score) called x_data, and one for the dependent variable (admission) y_data.
The exam score values are given as floats and the admission value is given as a binary value – 1 for admitted and 0 for not admitted. I cast this to an int to work with libsvm.
x_data = []
y_data = []
# Load data from CSV file into two arrays - one for independent variables X and one for the dependent variable Y
CSV.foreach("./data/admission.csv", :headers => false) do |row|
x_data.push( [row[0].to_f, row[1].to_f] )
y_data.push( row[2].to_i )
end
Next we need to divide the data into training data and testing data. This will help ensure the support vector machine we will train is not going to be over-fitted to our data. We allocate 20% of data for testing and 80% for training:
# Divide data into a training set and test set test_size_percentange = 20.0 # 20.0% test_set_size = x_data.size * (test_size_percentange/100.to_f) test_x_data = x_data[0 .. (test_set_size-1)] test_y_data = y_data[0 .. (test_set_size-1)] training_x_data = x_data[test_set_size .. x_data.size] training_y_data = y_data[test_set_size .. y_data.size]
With our data ready we are ready to setup our SVM model. The first step is to define the SVM we want to create.
For our example we are going to create SVM with a Gaussian kernel (in libsvm called Radial Basis Function (RBF)). We set epsilon to 0.001, C to 1 and the gamma parameter for the RBF to 0.01. Later we will see if these are good values for the parameters and walk through an approach for finding better values.
# Setup SVM parameters parameter = Libsvm::SvmParameter.new parameter.cache_size = 1 # in megabytes parameter.eps = 0.001 parameter.c = 1 parameter.gamma = 0.01 parameter.kernel_type = Libsvm::KernelType::RBF
With the model parameters setup we convert our datasets from regular Ruby arrays into LibSVM feature vectors. This is needed to train and test the SVM using rb-libsvm.
# Convert into proper feature arrays for Libsvm
test_x_data = test_x_data.map {|feature_row| Libsvm::Node.features(feature_row) }
training_x_data = training_x_data.map {|feature_row| Libsvm::Node.features(feature_row) }
Now that we have our training features converted to libsvm features we can define our problem in libsvm.
To define a problem we must provide the training features and the expected outputs like this:
# Define our problem using the training dat problem = Libsvm::Problem.new problem.set_examples(training_y_data, training_x_data)
With our problem defined we can train the SVM model:
# Train our model model = Libsvm::Model.train(problem, parameter)
Having our model trained we can now use it to make predictions. Here is an example of making a simple prediction of admission, if the student scored 45 on the first exam and 85 on second. Note how we convert our input parameters to a libsvm feature vector before calling the predict method.
The predict method will return the class, so that is 0 for not admitted and 1 for admitted.
# Predict single class
prediction = model.predict( Libsvm::Node.features([45, 85]) )
# Round the output to get the prediction
puts "Algorithm predicted class: #{prediction}"
Now that we know how to make a prediction, we can measure our classification accuracy using the test data we set aside before training the algorithm. This is done by making a prediction for each data row and comparing that to the actual admission data.
predicted = []
test_x_data.each do |params|
predicted.push( model.predict(params) )
end
correct = predicted.collect.with_index { |e,i| (e == test_y_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
puts "Classification Accuracy: #{((correct.to_f / test_set_size) * 100).round(2)}% - test set of size #{test_size_percentange}%"
The full source for our SVM in Ruby can be found here.
Executing this program gives us the following output:
$ ruby svm.rb Algorithm predicted class: 1.0 Classification Accuracy: 90.0% - test set of size 20.0%
A classification accuracy of 90% is not the best. Especially not comparing to our 95% accuracy using logistic regression and 100% when using a neural network. In the section below we discuss how to improve this performance.
Finding the optimal C and gamma values for a Gaussian SVM kernel
In our example above we got a 80% classification accuracy using our SVM model. This is not very good and we know we can do better for the data we have available. To increase our accuracy we can modify the C and gamma parameters of a SVM.
The C parameter is similar to the regularization parameter λ we know from other machine learning models, only C is the inverse of λ. That is a larger C will give you lower bias and higher variance a model will have, where a low C will give you high bias and low variance.
The Gamma parameter is a parameter specific to the Gaussian kernel (RBF in libsvm). The gamma parameter define how far a single training example will have influence. So that is how much influence will a single training example have on examples that are further away from the training example.
To find the optimal C and gamma parameters we are going to create a program that iterates through possible values of C and gamma, and measures the classification accuracy for each combination and finds the best combination. Lastly the program will test the selected combination of C and gamma on unknown data to measure its general classification accuracy.
To do this we must now split our data into 3. A training dataset using to train the model, a validation dataset used to test combinations of C and gamma and select the best one, and lastly a test dataset used to test the model using the optimal C and gamma parameters to find the classification accuracy. We use a split of 70% training data, 15% validation data and 15% test data.
Setting up the datasets
To import our data from the CSV files and split into the 3 datasets and convert them to libsvm feature vectors we do the following:
require 'csv'
require 'libsvm'
x_data = []
y_data = []
# Load data from CSV file into two arrays - one for independent variables X and one for the dependent variable Y
CSV.foreach("./data/admission.csv", :headers => false) do |row|
x_data.push( [row[0].to_f, row[1].to_f] )
y_data.push( row[2].to_i )
end
# Divide data into a training set and test set
validation_size_percentange = 15.0 # 15%
validation_set_size = x_data.size * (validation_size_percentange/100.to_f)
test_size_percentange = 15.0 # 20%
test_set_size = x_data.size * (test_size_percentange/100.to_f)
validation_x_data = x_data[0 .. (validation_set_size-1)]
validation_y_data = y_data[0 .. (validation_set_size-1)]
test_x_data = x_data[validation_set_size .. (validation_set_size+test_set_size-1)]
test_y_data = y_data[validation_set_size .. (validation_set_size+test_set_size-1)]
training_x_data = x_data[(validation_set_size+test_set_size) .. x_data.size]
training_y_data = y_data[(validation_set_size+test_set_size) .. y_data.size]
# Convert into proper feature arrays for Libsvm
validation_x_data = validation_x_data.map {|feature_row| Libsvm::Node.features(feature_row) }
test_x_data = test_x_data.map {|feature_row| Libsvm::Node.features(feature_row) }
training_x_data = training_x_data.map {|feature_row| Libsvm::Node.features(feature_row) }
With the datasets created we can define our problem:
# Define our problem using the training dat problem = Libsvm::Problem.new problem.set_examples(training_y_data, training_x_data)
Testing C and gamma values
To test our C and gamma values I setup an array of possible values for C and gamma and iterate over the array twice.
Once to test the C parameter and one to test the gamma parameter. For each test we measure the classification accuracy using our validation dataset. If the accuracy is found to be better than the previous best accuracy we store the accuracy, C and gamma values.
## Lets try to find the best C and sigma values
posible_values = [0.0001, 0.0005, 0.0001, 0.0005, 0.001, 0.005, 0.01, 0.05, 0.1, 0.5, 1, 5, 10, 50, 100, 500]
best_c, best_gamma, best_accuracy = 0,0,0
posible_values.each do |test_c|
posible_values.each do |test_gamma|
parameter = Libsvm::SvmParameter.new
parameter.cache_size = 1 # in megabytes
parameter.eps = 0.001
parameter.gamma = test_gamma
parameter.c = test_c
parameter.kernel_type = Libsvm::KernelType::RBF
# Train our model
model = Libsvm::Model.train(problem, parameter)
predicted = []
validation_x_data.each do |params|
predicted.push( model.predict(params) )
end
correct = predicted.collect.with_index { |e,i| (e == validation_y_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
accuracy = ((correct.to_f / validation_set_size) * 100).round(2)
if( accuracy > best_accuracy)
best_accuracy = accuracy
best_c = test_c
best_gamma = test_gamma
puts "New best! Classification Accuracy: #{accuracy}% - C=#{test_c}, gamma=#{test_gamma}"
end
end
end
Testing the optimal C and gamma values
Having found our optimal C and gamma values we can now test them on our test dataset and measure the actual generalization classification accuracy like this:
# Setup the model with optimal parameters and calculate the test accuracy
parameter = Libsvm::SvmParameter.new
parameter.cache_size = 1 # in megabytes
parameter.eps = 0.001
parameter.gamma = best_gamma
parameter.c = best_c
parameter.kernel_type = Libsvm::KernelType::RBF
# Train our model
model = Libsvm::Model.train(problem, parameter)
predicted = []
test_x_data.each do |params|
predicted.push( model.predict(params) )
end
correct = predicted.collect.with_index { |e,i| (e == test_y_data[i]) ? 1 : 0 }.inject{ |sum,e| sum+e }
accuracy = ((correct.to_f / test_set_size) * 100).round(2)
puts "Test Generalization Accuracy: #{accuracy}% - C=#{best_c}, gamma=#{best_gamma}
The full source code for finding the best C and gamma values can be found here.
Executing the script gives the following output:
$ ruby svm_find_parameters.rb New best! Classification Accuracy: 53.33% - C=0.0001, gamma=0.0001 New best! Classification Accuracy: 73.33% - C=0.1, gamma=0.0005 New best! Classification Accuracy: 80.0% - C=0.1, gamma=0.001 New best! Classification Accuracy: 93.33% - C=0.5, gamma=0.0001 New best! Classification Accuracy: 100.0% - C=500, gamma=0.0005 Test Generalization Accuracy: 100.0% - C=500, gamma=0.0005
This shows that with the correct parameters our SVM can get a classification accuracy of 100% on our test dataset. This shows that a Support Vector Machine with a Gaussian kernel can be just as a good at solving our problem as a Neural Network.
To see how this problem was solved using a neural network read this blog post.
great stuff
Superb!!! Great article ..Thank you very much!!
This is a very well written and well thought out example. It builds nicely upon each step and therefore is easy to follow. I look forward to reading through the other AI and ML posts.